Serverless ETL Pipelines

Noel Llevares
Data EngineerIn Assignar, we have several requirements for delivering business analytics both to our customers and for our own internal use. To accommodate those requirements, we use extract-transform-load (ETL) pipelines to process our customer data and prepare it for analytical queries. In this article, we describe how we use serverless architectures to implement the ETL strategies we employ to deliver business intelligence to our customers.
Assignar Insights
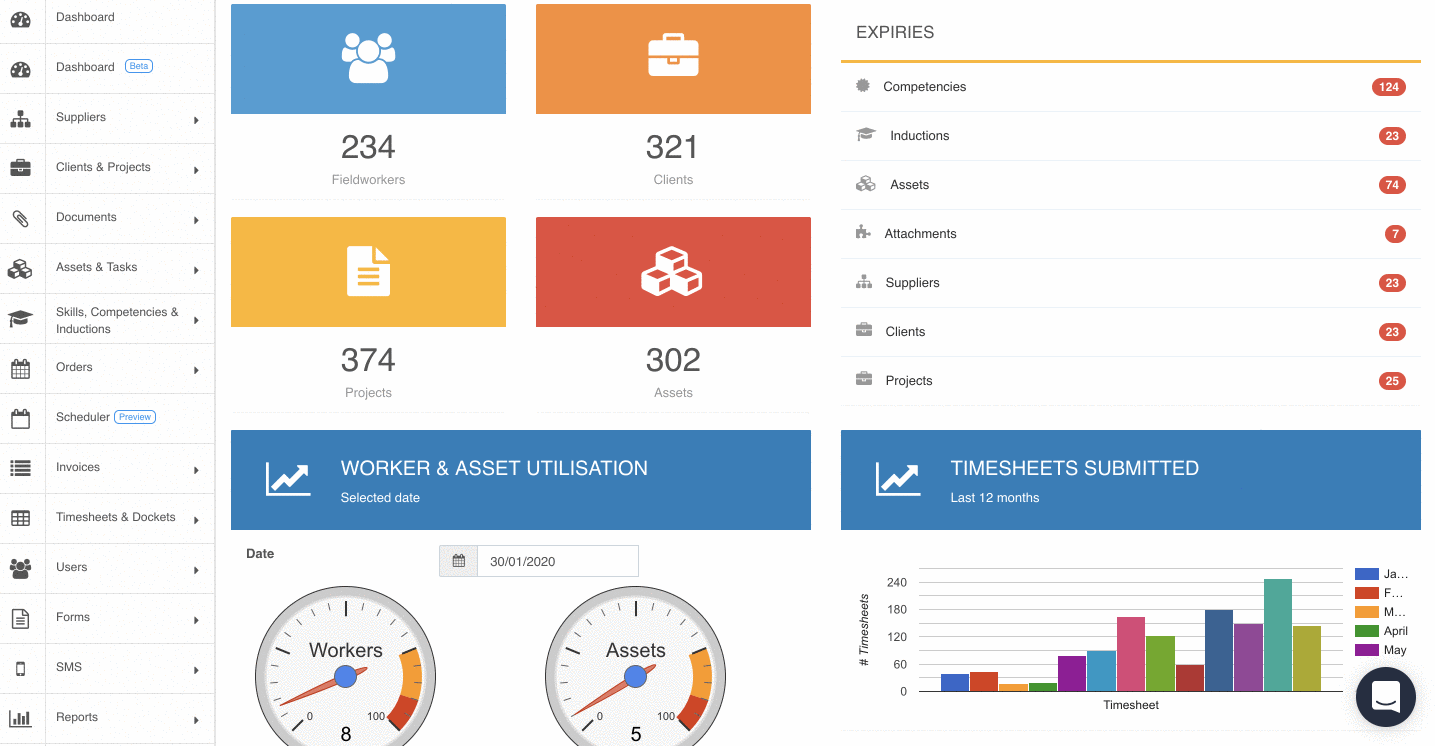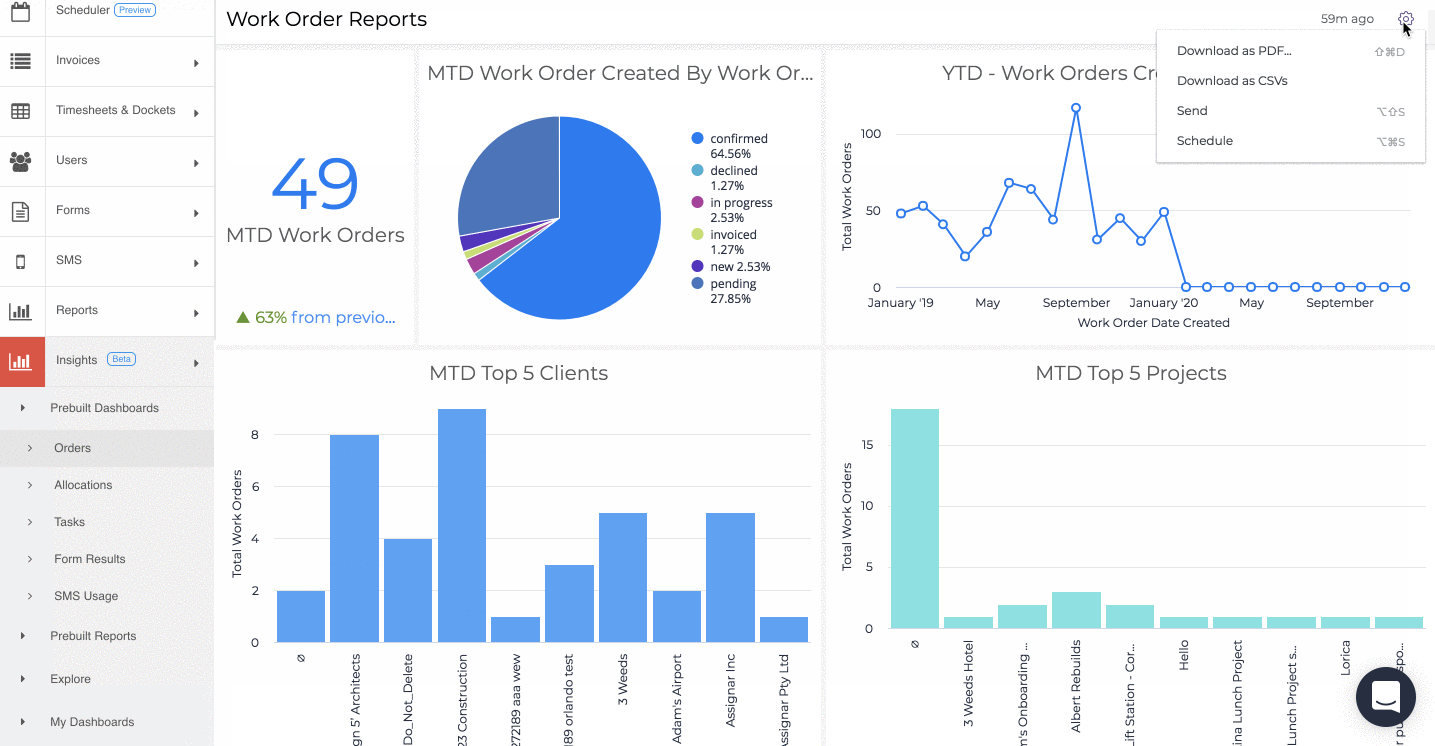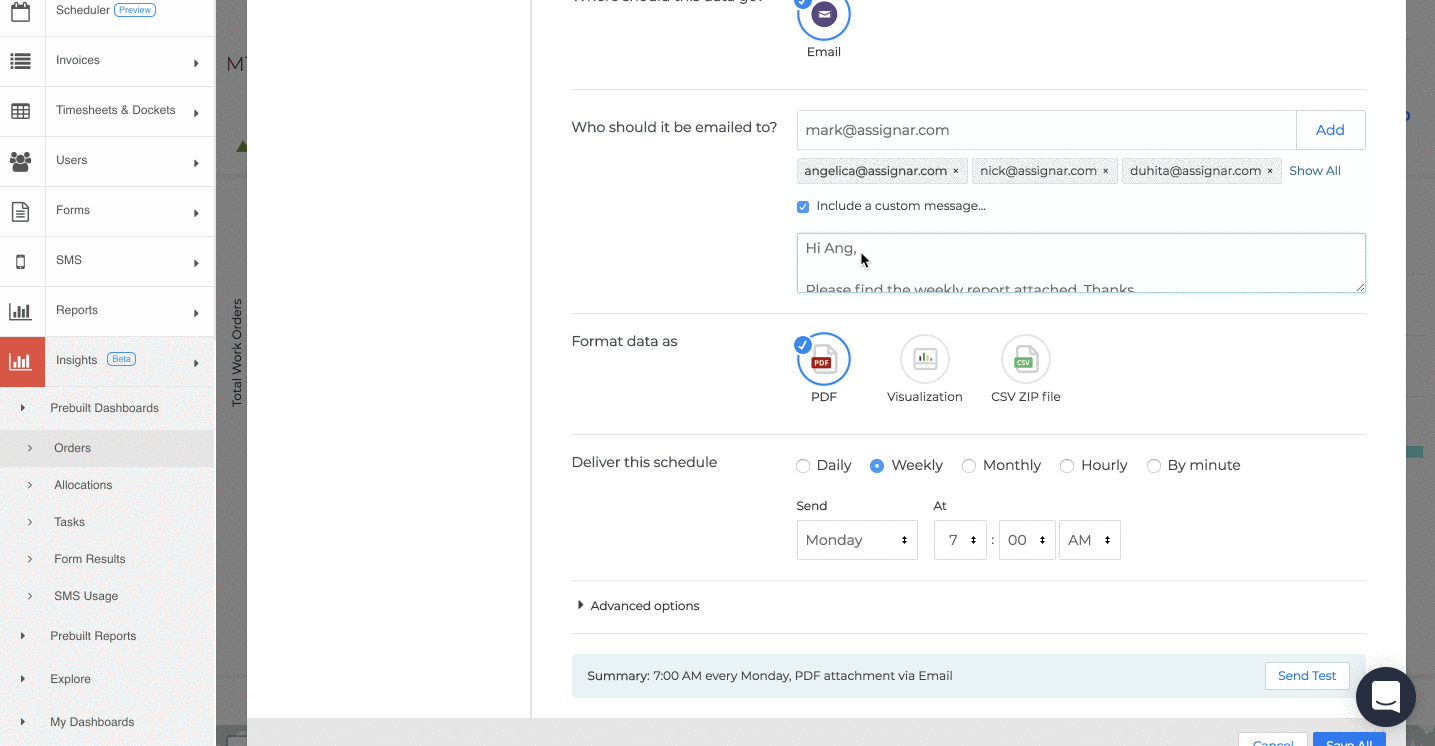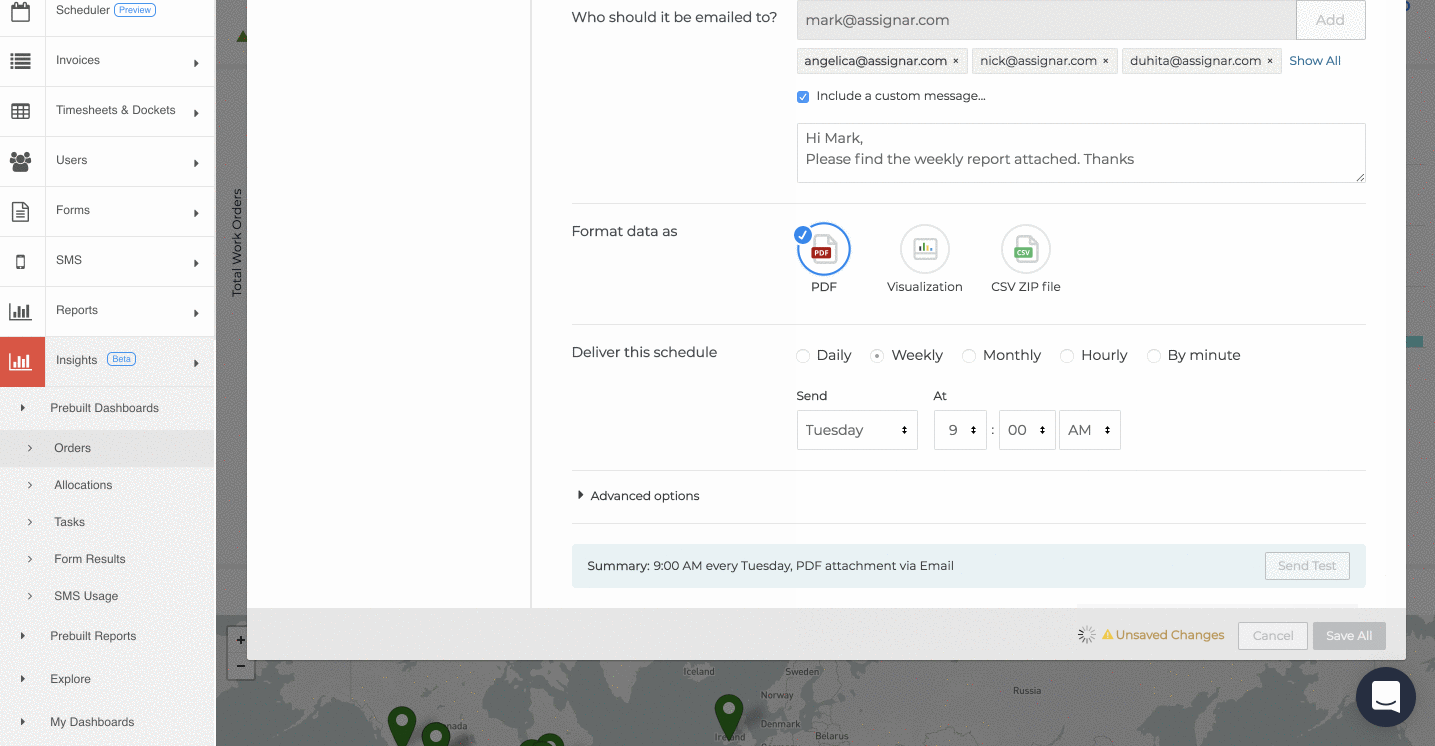
One of Assignar's most powerful features is called Insights. Insights give our users the ability to create customized real-time reports, charts, and alerts to help them monitor their operations and track progress. By making the data easily accessible and understandable, our users can make better decisions for their businesses.
Database Architecture Overview
Multi-tenancy
Assignar is a B2B SaaS platform. As such, we isolate our customers data from each other by provisioning a separate database for each one.

Optimization for Analytical Queries
Transactional data is usually stored in a manner that is optimized for writes and consistency. While this is ideal for storing day-to-day data, it makes the high-volume, read queries typical of business analytical queries slow. Large queries involving millions of rows joined from ten or more tables also causes a big burden to our database.
In order for us to deliver fast results for business analytical queries, we have to prepare the data in a way that is optimized for large reads. This is where the ETL process comes in.

Assignar Insights only reads from the analytical tables. Because data in the analytical tables are optimized for analytical queries, we can provide fast results with less computational burden on the database.
Challenges
As the transactional data gets duplicated into our analytical tables, this poses a few challenges:
- Our customers would want to use Insights to make important business decisions. Therefore, the data from the reports they get in Insights should be up-to-date. (Real-time ETL for a single newly-created/updated/deleted rows.)
- As we keep improving our platform to cater to the needs of our customers, there will be times we would need to change the data structures and database schemas, we would need a way to be able to recreate entire analytical tables when the need arises. (Full table ETL to recreate an entire analytical table based on new data structure/schema.)
Other technical requirements include being able to control when to execute full table ETL at the best time when normal day-to-day operations of the database cluster would not be affected.
Solutions
The two ETL processes above are triggered via events:
- The Real-time ETL is triggered via an event from our platform. This should happen in response to a user creating, updating, or deleting an entity.
- The Full Table ETL is not triggered automatically. This is because we only need to execute it when we need to. When we do need it, we want it to execute during off-business hours to minimize the impact to our customers.
Because these solutions lend themselves well to an event-driven architecture, we have chosen to build our solutions on top of serverless architectures such as AWS Lambda, S3, etc.
Real-time ETL
For some of our entities where the ETL requirement is simply to copy or calculate a certain value to be stored to another table, database triggers. They are easy to implement and no additional infrastructure is needed.
However, we have some entities that require some transformation to happen before it gets written to the analytical tables. For example, a core feature of Assignar is the ability to create custom forms or dockets for the field workers to fill out and submit. Questions and response types can vary from customer-to-customer and even from form-to-form. To allow for this flexibility, our platform uses JSON documents to store these questions and responses in the database.
While using JSON documents works great for our platform, it is unusable for business analytics purposes. To make it usable for business analytics, we perform Real-time ETL when this entity is created, updated, or deleted.
Our platform broadcasts events for every user action that leads to a successful database transaction (e.g. FormSubmitted) into an SNS topic.

These events can be "listened to" by Lambda Functions to perform other things such as sending email/push notifications, and in this case, to perform real-time ETL on the respective entities. This Lambda Function will extract the row(s) from the transactional table, do necessary transformations of the rows, and then write those transformed rows into the analytical tables.
Full Table ETL
Sometimes, improving our platform also entails making changes to our underlying data structures and how we store and retrieve them. This may mean that the previous transformations that we have materialized into the analytical tables may not be relevant anymore. So, we may have to perform migrations to update the analytical tables.
For migrations that can be performed by the database itself via DDL or DML statements, we execute those migrations via SQL migrations. For those that cannot be done by the database itself, we have to execute the same transformations that we do in Real-time ETL but this time we do it for each row.
We would like to reuse the same transformation logic we used in Realtime ETL but triggering the Real-time ETL Lambda for each and every row when you have billions of rows to extract, transform, and load will not be scalable.
Instead of doing that, we use a Full Table ETL Lambda Function with the same transform as the Real-time ETL Lambda, but extracts rows from the transactional tables in bulk.
The following snippet illustrates how we do it.
A Full Table ETL is going to be a long-running process and potentially can be a burden on the database cluster, so it is best that we only trigger this manually as a one-off process that needs to be executed as the need arises. Also, depending on the data size and the complexity of the transformation logic, the entire ETL process may not finish within the execution limits of AWS Lambda. We will explore how we tackled this in a follow-up article.
Conclusion
ETL processes are triggered either via real-time events from user actions or from manual triggers. As it is event-driven by nature, it is easy to handle them in a serverless way with very minimal infrastructure and costs.