Topic Modelling - Assignar Forms Classification

Zarmina Muhammad
Data AnalystI would like to share my perspective and experience on selecting ‘Topic Modeling’ algorithm for Short text form titles i.e., Latent Dirichlet Allocation and Gibbs Sampling Dirichlet Multinomial Mixture and how the modelling is done along with training of the model.
In the Assignar Forms Library project, the first milestone was to identify the top categories that the forms are occurring in. For form categorisation, we started from a simple solution followed by classical ML and deep learning approaches. The proposed structure was;
- Considering individual title as a category: The titles with the higher occurence count is considered as a category
- Defining Category variable: Defining Category variable to identify the categories from the titles Via SQL query.
- Traditional ML: Using the Dirichlet multinomial mixture clustering analysis to identify the top 5 topics in the form titles and repeating the same process for the top 10 questions.
After review of results from the first analysis and whilst considering the most frequently occurring title as a top category, did not work since 2 out of 5 most occurring titles were belonging to the same category type. This consequently led to the false results. The second analysis, i-e defining categories via SQL query also failed as it classified a huge volume of titles as 'Others' and there were high chances of wrong placement of the titles in their respective categories as the entire analysis was performed manually. The third and the most trusted approach was the traditional ML technique. However, deciding the right NLP model was a daunting task.
Model Selection: LDA Vs GSDMM
The most popular Topic Modeling algorithm is LDA, Latent Dirichlet Allocation which assumes that a document can have multiple topics and it provides better results on large size documents (>50 words)[4].
For topic modelling of form titles, GSDMM (Gibbs Sampling Dirichlet Multinomial Mixture) is preferred over LDA since due to small size texts of the form titles, LDA performance could lead to poor results. GSDMM is essentially a modified LDA (Latent Dirichlet Allocation), which assumes that a document (title) encompasses 1 topic. This differs from LDA which assumes that a document can have multiple topics.
GSDMM Introduction
GSDMM principle can be explained using an analogy “Movie Group Approach” (this library has a function mgp as well that refers to MovieGroupProcess)[3]. For instance, think of a student’s group (documents/titles) all having a list of their favourite movies (words). These students are further indiscriminately allocated a ‘K’ number of tables. On professor’s directions these students must mix up tables with following 2 rules:
- Completeness: Choose a table with more students
- Homogeneity: Choose a table where students share similar movie interests
This shuffling within the tables continues until a point reaches where the number of students on each table as well as the type of students will not change[2,3].
Model Parameters:
In GSDMM, the Dirichlet distribution refers to the Beta distribution across multiple dimensions (form titles). These are the probabilities that correspond to the prior state or likelihood of a document joining a cluster as well as the similarity of that document to the cluster.
Two factors (alpha and beta[1,2] described below) control the shape of the Beta distribution. Alpha signifies that the same clusters are important while beta signifies that similarity in the words is important.
- Alpha: This affects the shape of the probability distribution (i.e. the probability that a document will be grouped into a cluster). In above case, alpha refers to the student deciding the table.
- Beta: This determines the similarity of words in one title document, to those of words in another title(document). In the above movie example, it refers to the probability of students choosing a table with similar movie choices.
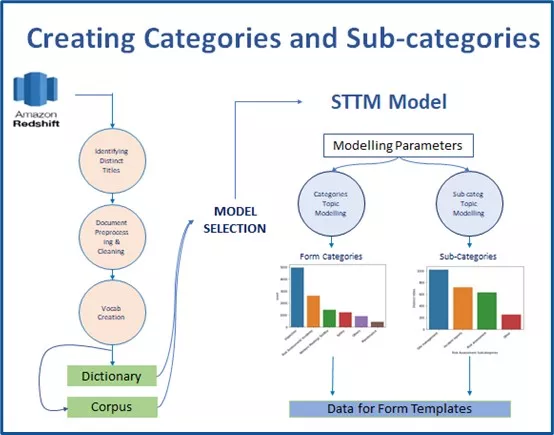
GSDMM Implementation
In this section we have used STTM pipeline for topic modelling of forms titles to identify the categories these titles are occurring in. The first step was to download the STTM script[4] from Github into AFL repository.
Required Libraries
Categorisation & Tokenisation
Data pre-processing with Bigrams and Trigrams:
The titles in the forms data requires preprocessing for the topic model algorithm to process it. The pre-processing[4,5] involved data cleaning step where for these titles:
- Conversions into lowercase letters was done
- Removals of empty strings, links, hashtags, emojis & digits were done
- Removals of stop words were done
- Lemmatisation was performed to shorten the words to its root
- Removal of duplicates was completed that may have led to otherwise false results
- Tokenisation was done i.e., to split up the titles into array of words
- Bigrams was performed i.e., grouping 2 words in the titles as a token (This provided information about the kind of words occurring in each cluster)
- Trigrams was performed i.e., grouping 3 words in the title as a token (This helped in identifying and naming the topic/cluster)
Bigrams and trigrams[5] help in identifying and assigning a proper name to the topic/cluster.
Training the Model:
Training the Model: The hyperparameter structure[1,5] of the GSDMM model consists of value
- K= 5. This refers to the number of clusters/topics/categories.
- Alpha=0.1 (set to default)
- Beta= 0.1 (set to default)
- n_iter = 40 GSDMM converges relatively faster but to get more stable output, the iterations were set to 40
Interpretation of Results
Naming the topics, obtained by the GSDMM model was performed manually based on the type of words that are clustered within each topic. To do so, first, all the words and their occurrence frequency within each topic are analysed[5]. Subsequently based on the words, dictionary of each topic/cluster names were assigned to each topic e.g, Checklist, prestart, precheck, inspection etc makes the Inspection category similarly risk, assessment, incident, traffic, accident etc contributes to Risk Assesment/ Incidents.
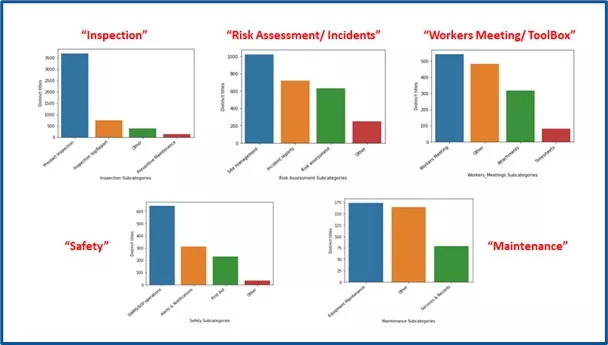
Based on the topic modeling results, the 5 topics/clusters were named as following:
- Inspection
- Risk Assessment/Incidents
- Workers Meeting/Toolbox
- Safety
- Maintenance

The words/tokens that were clustered within each topic (by the GSDMM model), were used to define a new variable Form_category.
Insights from the 'Form_category' variable
Visualizing the Form_Category, created from the results of topic modelling, clearly shows that within the forms data the most occurring category with distinct titles is ‘Inspection’. All other categories include:
Topic modelling to identify top titles within each category
Like the ‘Form_Categories’, GSDMM topic modelling was performed to identify the most occurring titles within each category. The difference highlights that topic modelling for titles does not require the entire data, thus as a prerequisite the data for each category was filtered. Finally, the subset of data was trained to get the desired titles.
Data Pre-processing, Modelling & Interpretation of Results
These steps were like that for Form_category, with the only exception that the data being a subset of each individual category under analysis and hence the entire dataset is not considered. Once the topic modeling was performed for all the Form_categories and the clusters were produced because of topic modelling, just like the form category, a new variable subcategory/title was created from the words (within each cluster/topic produced by GSDMM for each individual category).
Below figure represents the subcategories distribution within each form_category & within the forms data.
Next Step
Once these categories and the associated titles within each category are identified via the GSDMM topic modelling, the forms data including these new features ‘Form_category’ and ‘From titles’ are used to create form templates via sentence embedding and clustering.
Reference
- https://github.com/rwalk/gsdmm
- https://dl.acm.org/doi/10.1145/2623330.2623715
- https://towardsdatascience.com/a-unique-approach-to-short-text-clustering-part-1-algorithmic-theory-4d4fad0882e1
- https://towardsdatascience.com/short-text-topic-modeling-70e50a57c883
- https://brittanybowers.com/a-unique-approach-to-short-text-clustering-part-2-tweets-spread-like-wildfire/