How to use BERT Sentence Embedding for Clustering text

Nikita Sharma
Data Science InternThis post is about identifying context captured in text sentences and grouping/clustering similar sentences together. Understanding the context means that we need to understand every possible way a sentence could be written.
Here we will use BERT to identify the similarity between sentences and then we will use the Kmeans clustering approach to cluster the sentences with the same context together.
What is Word Embedding?
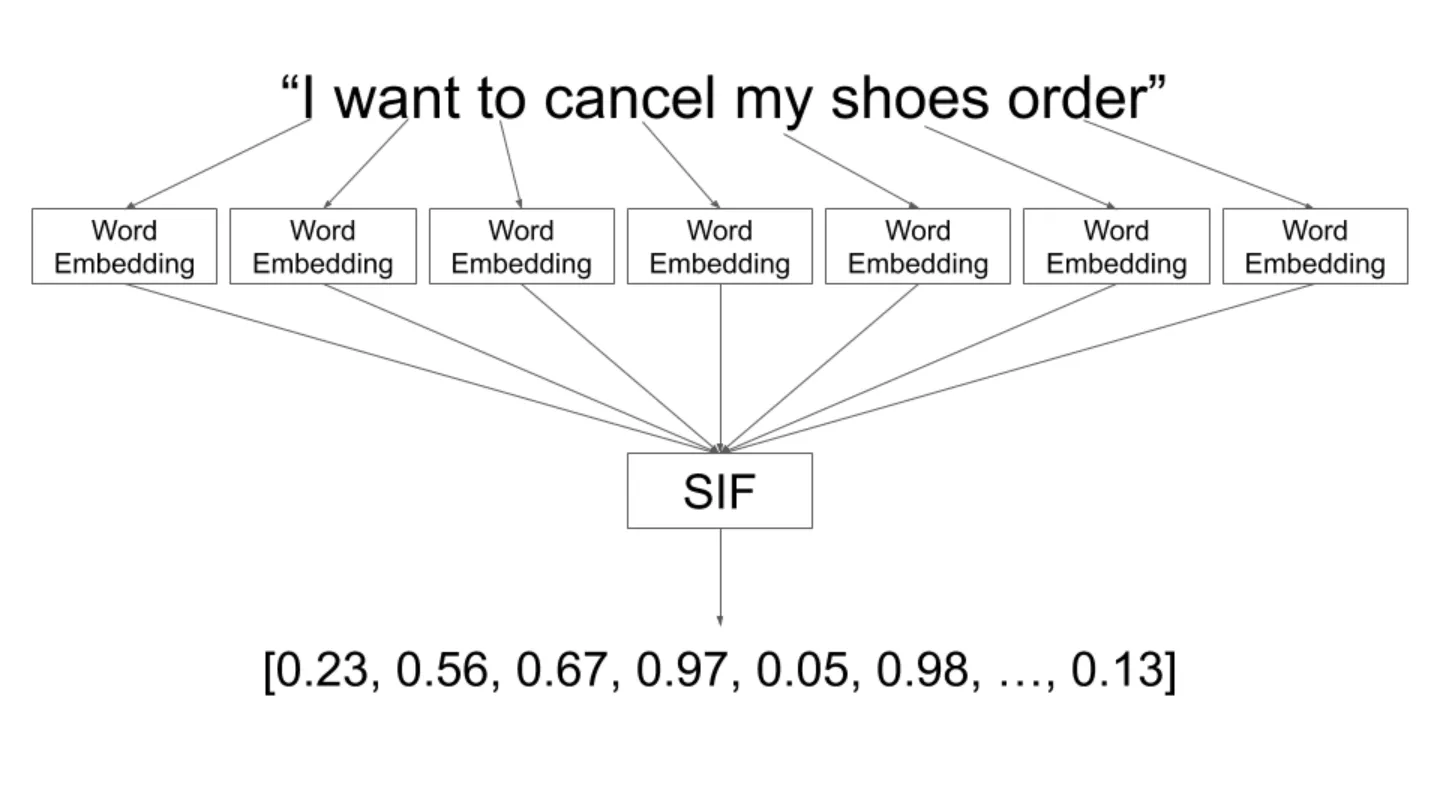
Word embedding is a numerical representation of text where words with similar meanings have a similar representation.
As depicted in the example below:

Contextual analysis can identify hidden features in words and sentences and can numerically identify similarity/distance from other words and sentences.
What is Sentence Embedding?
Sentence embeddings can capture semantic and contextual information from sentences rather than just looking at the literal word/tokens as done in traditional NLP approaches. Sentence Embedding converts the sentence into a vector of real numbers.
Introducing BERT
The BERT (Bidirectional Encoder Representations from Transformers) model created by Google is trained on entire Wikipedia which is like millions of documents and BERT already knows the context of the sentences. BERT is a bidirectional model that means it learns information from both the side of a token’s context during the training phase.
For example :
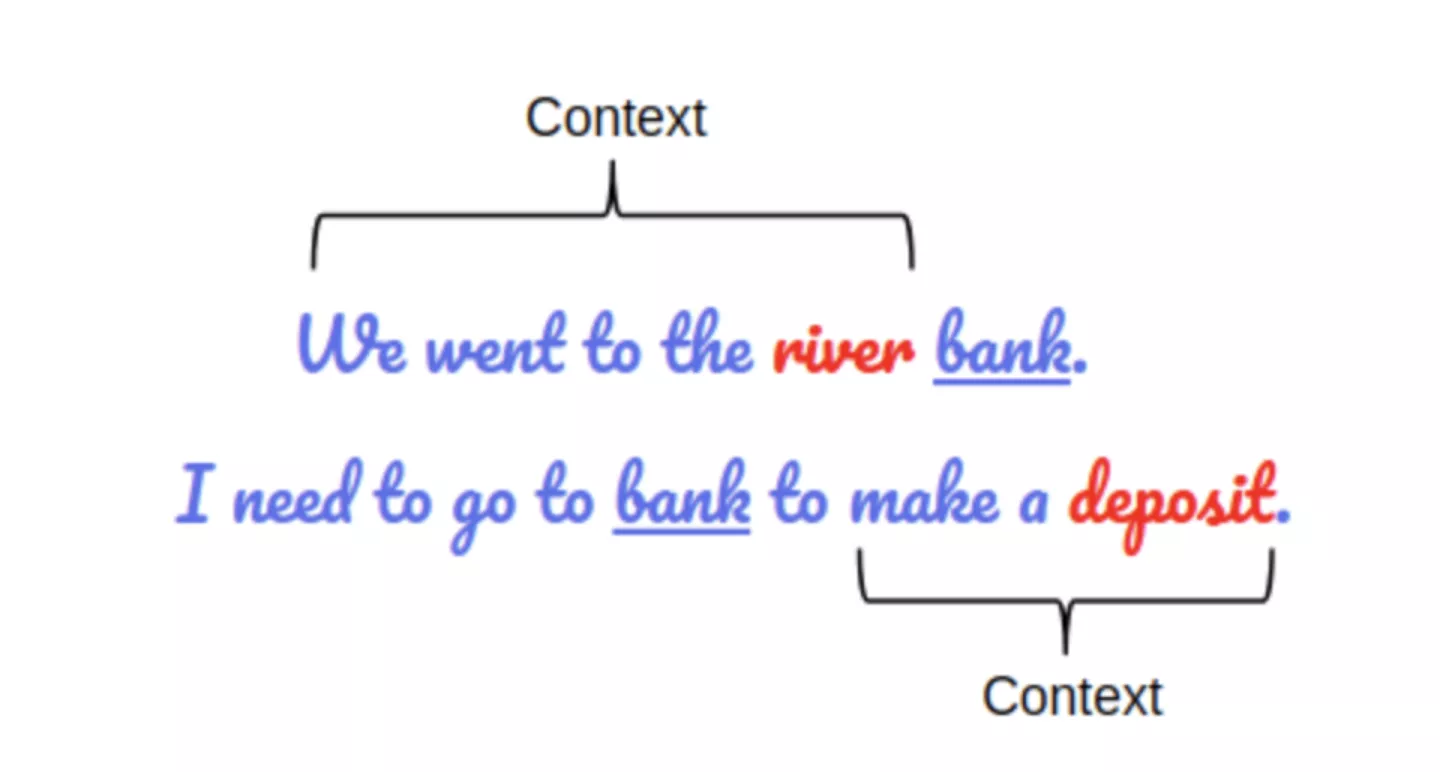 We can see in the above example that both the two sentences contain the word “bank” in it but having different meanings/contexts.
We can see in the above example that both the two sentences contain the word “bank” in it but having different meanings/contexts.
Applications of BERT
Following are the different applications of the Bert model :
- Next sentence prediction
- Sentence pair classification
- Single sentence classification
- Question and Answer prediction
- Sentence tagging
- Feature extraction: BERT can also be used to generate the contextualized embeddings and we can use those embeddings with our own model.
Computing sentence embedding
Here we have used random sentences as our play dataset to explain how to compute sentence embedding.
Let's have a look at the data

Let's create embedding for the above dataset
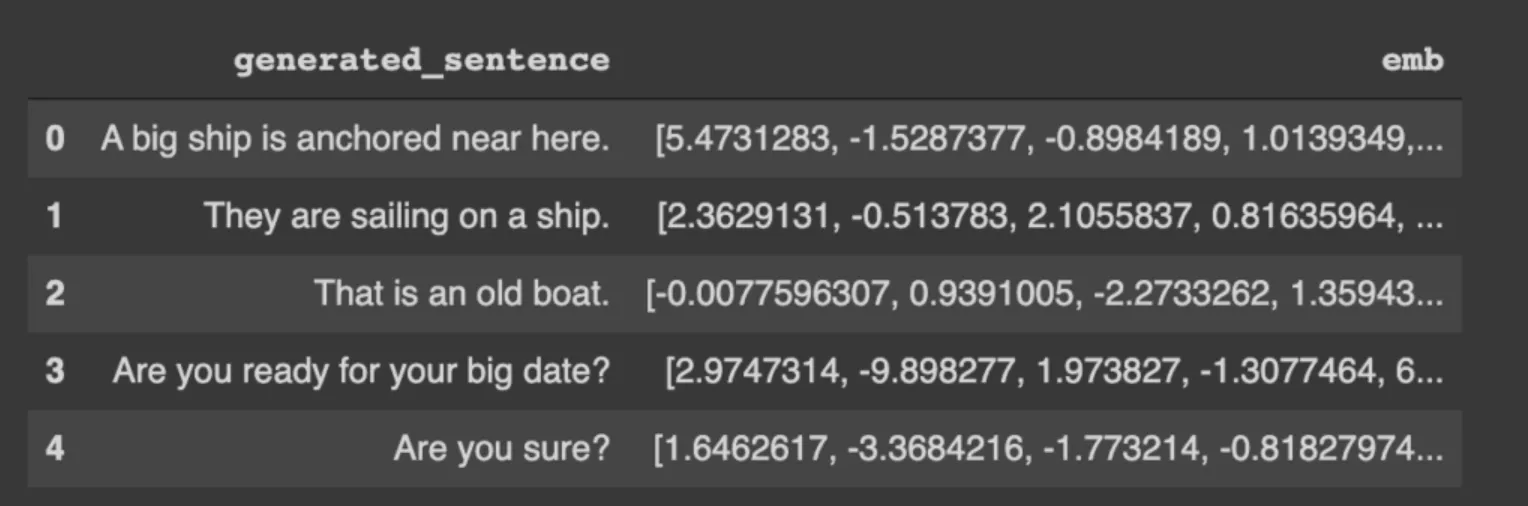
This will generate a 768-dimensional vector for each sentence. Each dimension represents a virtual feature that captures a particular meaning.
Clustering Sentences
Clustering was applied to the word embedding vectors derived from the sentences. Clustering was selected as the primary sentence categorization model since the data was unlabelled and an unsupervised algorithm had to be applied.
N number of clusters were identified from the sentence vectors in high 768-dimensional space. The primary purpose of these clusters was to identify similar sentences. The sentences in the same cluster contain the same context.
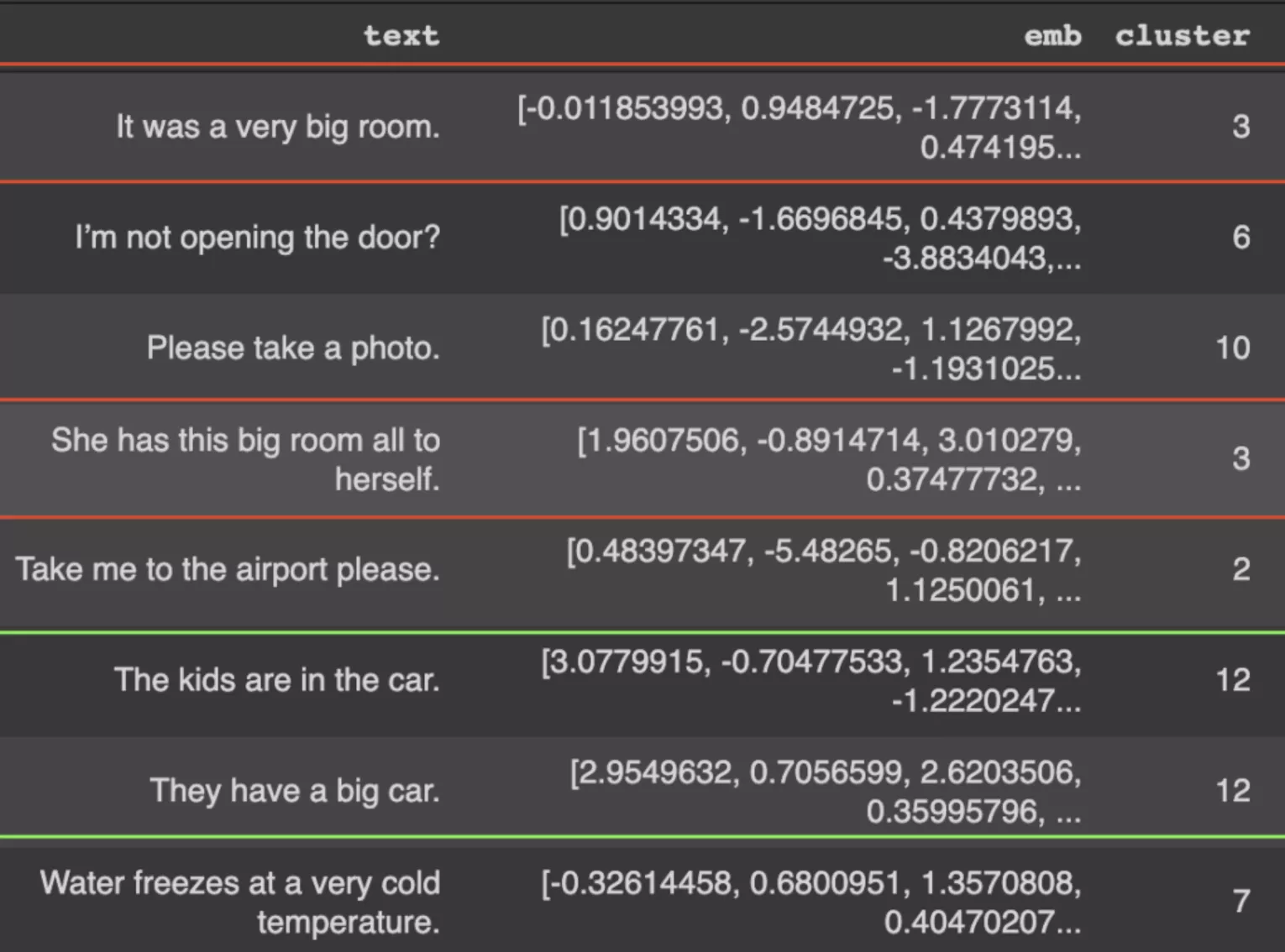
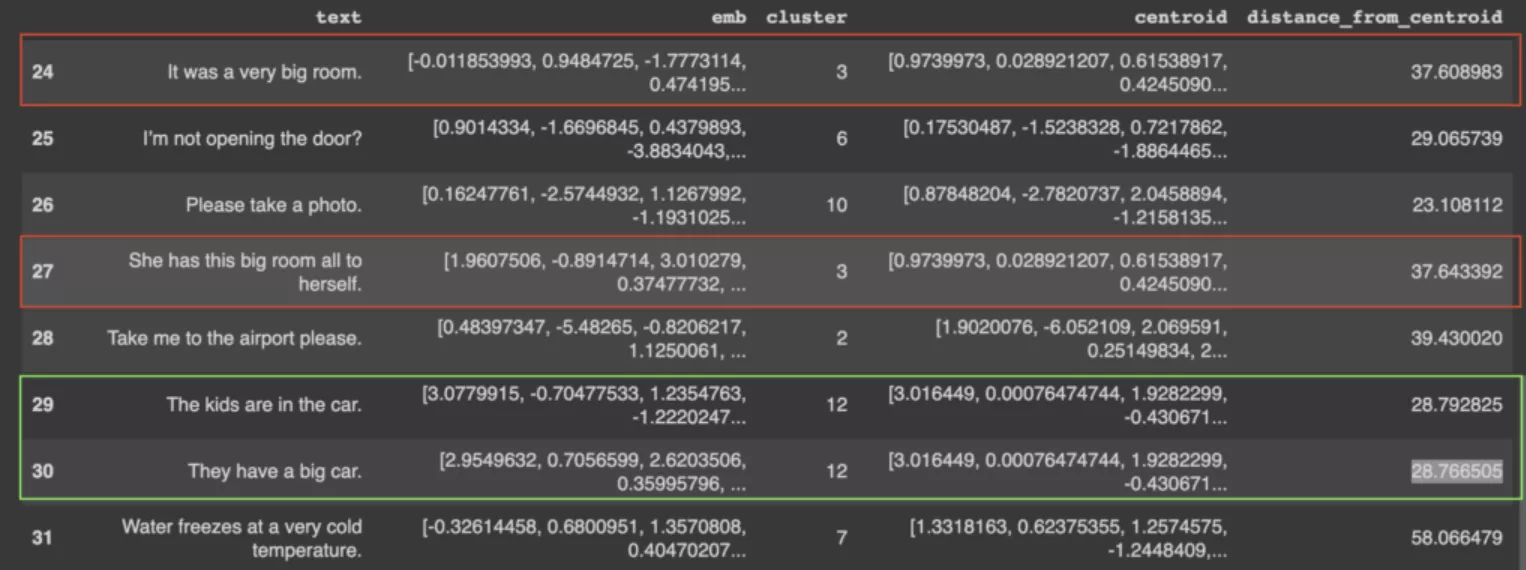
As we can see similar sentences are clustered together.
We can also compute the distance of the sentence from the centroid of the cluster which helps us to understand/extract the core context of the cluster.
Finishing notes
In this post, we talked about understanding the context and clustering them together. In the next post, we will talk about how we can visualize these text clusters in a 2-dimensional plane.